The Environment
In one of my deloyments we have a 5 node Hyper-V 2016 S2D Cluster. It’s based on Dell R730xd each with 2x 16core CPUs, 512GB RAM and storage of 2x 1,6TB NVMe cards, 4x 1,6TB SSD and 6x 4TB SATA drives. That gives us over 60TB of usable 3-tier storage. Network wise it’s using built-in 4x10GBit Qlogic NICs teamed and divided into vManagement, 2 vBackup and vSwitch for VMs. Storage wise it’s 2x10Gbit Mellanox CX-3 Pro per node.
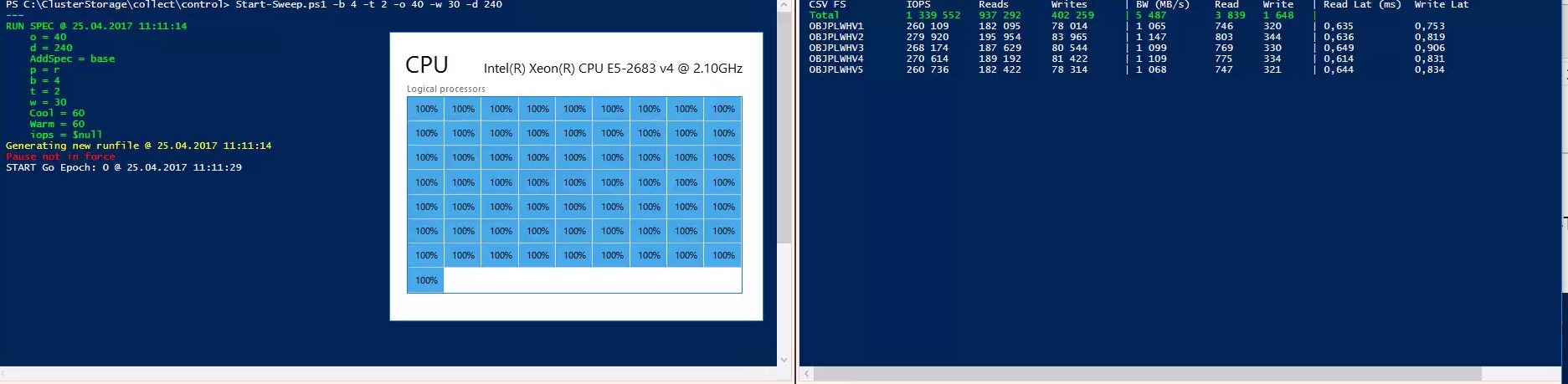
It’s been working great and we’ve achieved quite fancy numbers with it - over 1,3M IOPS during stress tests with VMFleet
The Issue
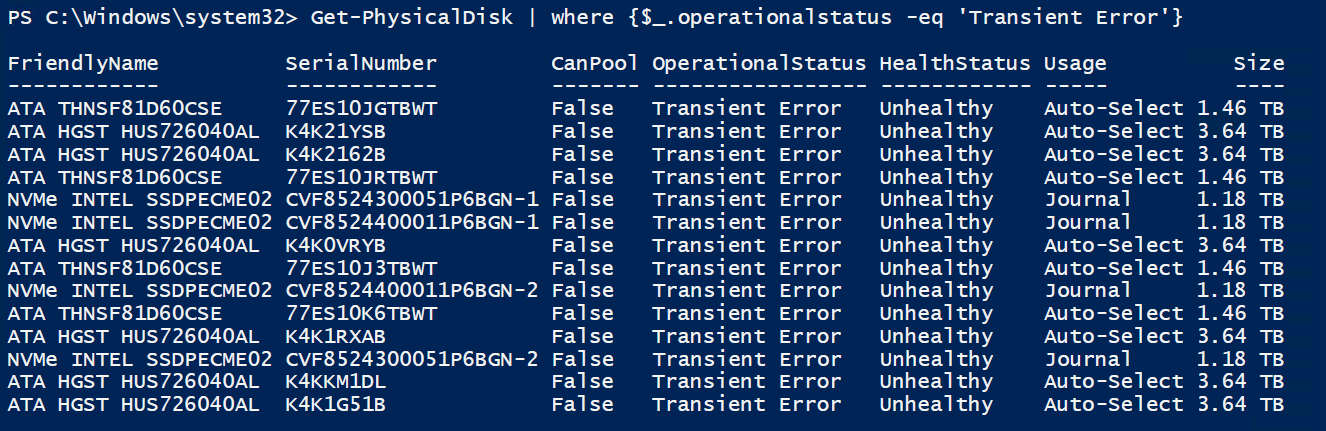
Anyway - time has come and we needed to expand the cluster with another node. While adding the node and then creating new vdisk we had a small issue. In the end it didn’t add the drives correctly to the cluster marking them as ‘transient error’:
We tried removing and resetting those disks:
But it didn’t work as we had one repair job lingering in the background:

(that CreateVirtualDisk is the one that failed).
The Resolution
As you can see above, all drives from the new node were reporting error status. Bringing back those drives was quite easy.
First, get all disks in the pool with error status, then set those disks as retired and finally remove them from the pool.
This set those drives in primodal pool on the host. Then I was able to add all drives back to the cluster. NVMe drives weren’t added at first so I’ve added them manually and set those NVMes to be used as cache (Usage Journal).
Here’s the code used to do this:
After this I started an Optimization Job:
Optimize-StoragePool -FriendlyName 'S2D on HVCL0'
and Get-StorageJob shows ‘something is happening’. As you can see, the ‘Repair” job that was lingering before, it’s running now:
